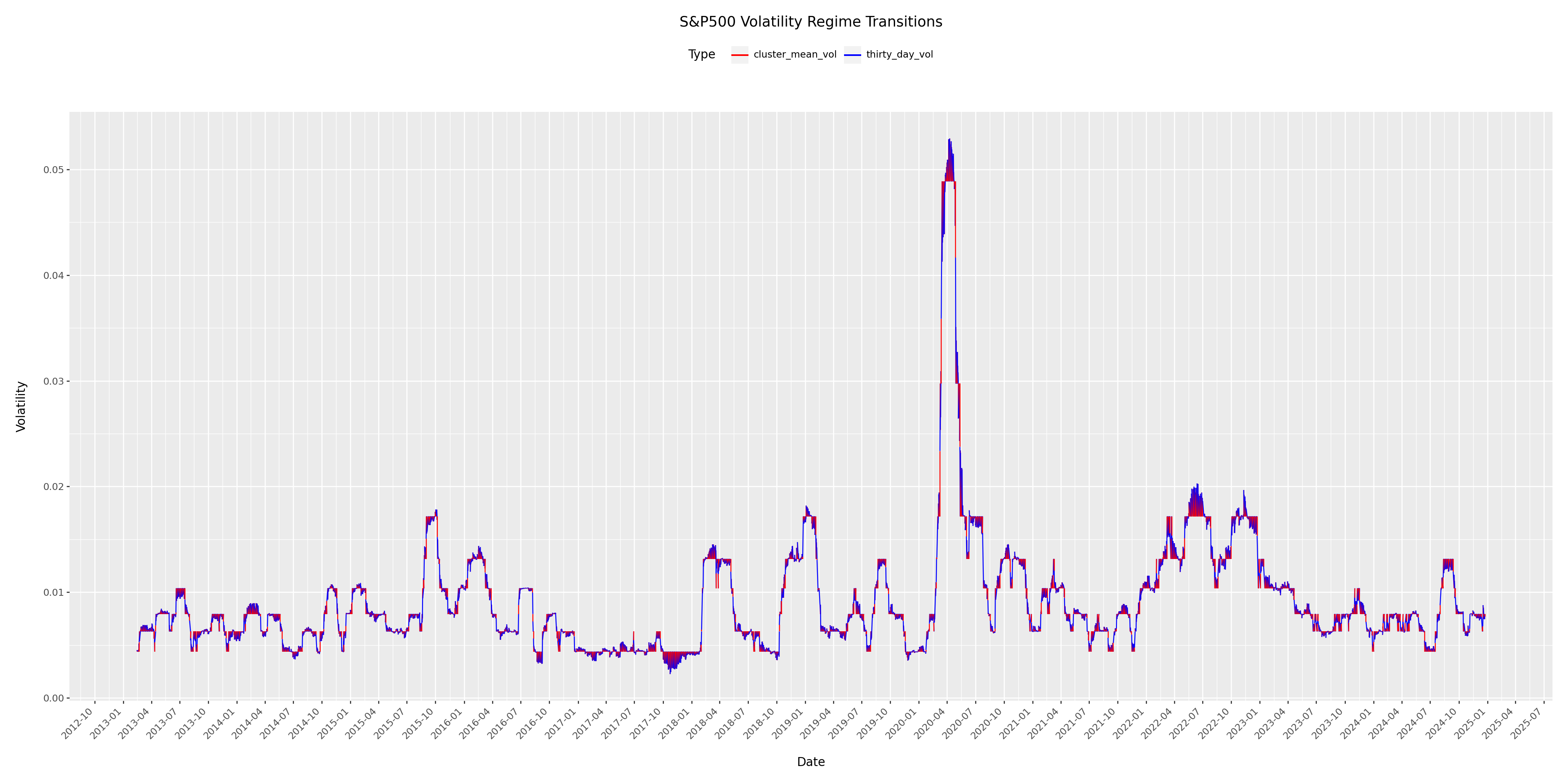
Goal: Use the broad stock index to model and understand the index volatility levels.
Key methodology: Use KMeans to build clustering model and then volatility regimes and then build transitional probability distribution among the regimes
Import Library
Code
import pyprojrootfrom pyprojroot.here import hereimport osimport yfinance as yfimport pandas as pdimport numpy as npimport ibisimport ibis.selectors as sfrom ibis import _ibis.options.interactive =Trueibis.options.repr.interactive.max_rows =20from plotnine import ggplot, geom_line, geom_path, aes, facet_wrap, labs, scale_x_continuous, theme, element_text, scale_y_continuous, scale_x_date, scale_color_manualimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn.preprocessing import MinMaxScaler
# Define the ticker symbol for the S&P 500 indexticker ='^GSPC'# Define the start and end datesstart_date ='2013-01-01'end_date ='2024-12-26'# Fetch the historical datasp500_data = yf.download(ticker, start=start_date, end=end_date, multi_level_index=False).reset_index()# Display the datasp500_data.head(10)
Date
Close
High
Low
Open
Volume
0
2013-01-02
1462.420044
1462.430054
1426.189941
1426.189941
4202600000
1
2013-01-03
1459.369995
1465.469971
1455.530029
1462.420044
3829730000
2
2013-01-04
1466.469971
1467.939941
1458.989990
1459.369995
3424290000
3
2013-01-07
1461.890015
1466.469971
1456.619995
1466.469971
3304970000
4
2013-01-08
1457.150024
1461.890015
1451.640015
1461.890015
3601600000
5
2013-01-09
1461.020020
1464.729980
1457.150024
1457.150024
3674390000
6
2013-01-10
1472.119995
1472.300049
1461.020020
1461.020020
4081840000
7
2013-01-11
1472.050049
1472.750000
1467.579956
1472.119995
3340650000
8
2013-01-14
1470.680054
1472.050049
1465.689941
1472.050049
3003010000
9
2013-01-15
1472.339966
1473.310059
1463.760010
1470.670044
3135350000
Clean data with ibis framework. We only need to keep Date and Close columns. Since data is downloaded live, we also archive a copy of data.
It is totally okay to use Pandas to clean the data. It’s just a personal preference that I prefer the modernized and portable syntax of ibis framework.
Code
# import to duckdb backend of ibis frameworksp500_data_ibis = ibis.memtable(data=sp500_data)sp500_data_cleaned = ( sp500_data_ibis.select("Date", "Close") .mutate(Date = _.Date.date(), Close = _.Close.round(digits =2)))# export a csv copysp500_data_cleaned.to_csv(path = os.path.join(output_dir, "sp500_close.csv")) # preview of datasp500_data_cleaned
return_window = ibis.window(preceding=30, following=0, order_by="Date")sp500_data_transformed = (sp500_data_cleaned.mutate(Previous_Close = _.Close.lag()) .mutate(Daily_Return = ((_.Close - _.Previous_Close)/_.Previous_Close).round(digits =6)) .mutate(thirty_day_vol = ibis.ifelse( _.Daily_Return.count().over(return_window) >=30, _.Daily_Return.std().over(return_window).round(digits =6), None)))sp500_vol_no_null = sp500_data_transformed.filter(_.thirty_day_vol !=None)sp500_vol_dates = sp500_vol_no_null.select("Date").mutate(index = ibis.row_number())sp500_vol = sp500_vol_no_null.select("thirty_day_vol")# bring to pandas dataframes to be more compatible with sklearn APIssp500_vol_pd = sp500_vol.to_pandas()
Train KMeans Model
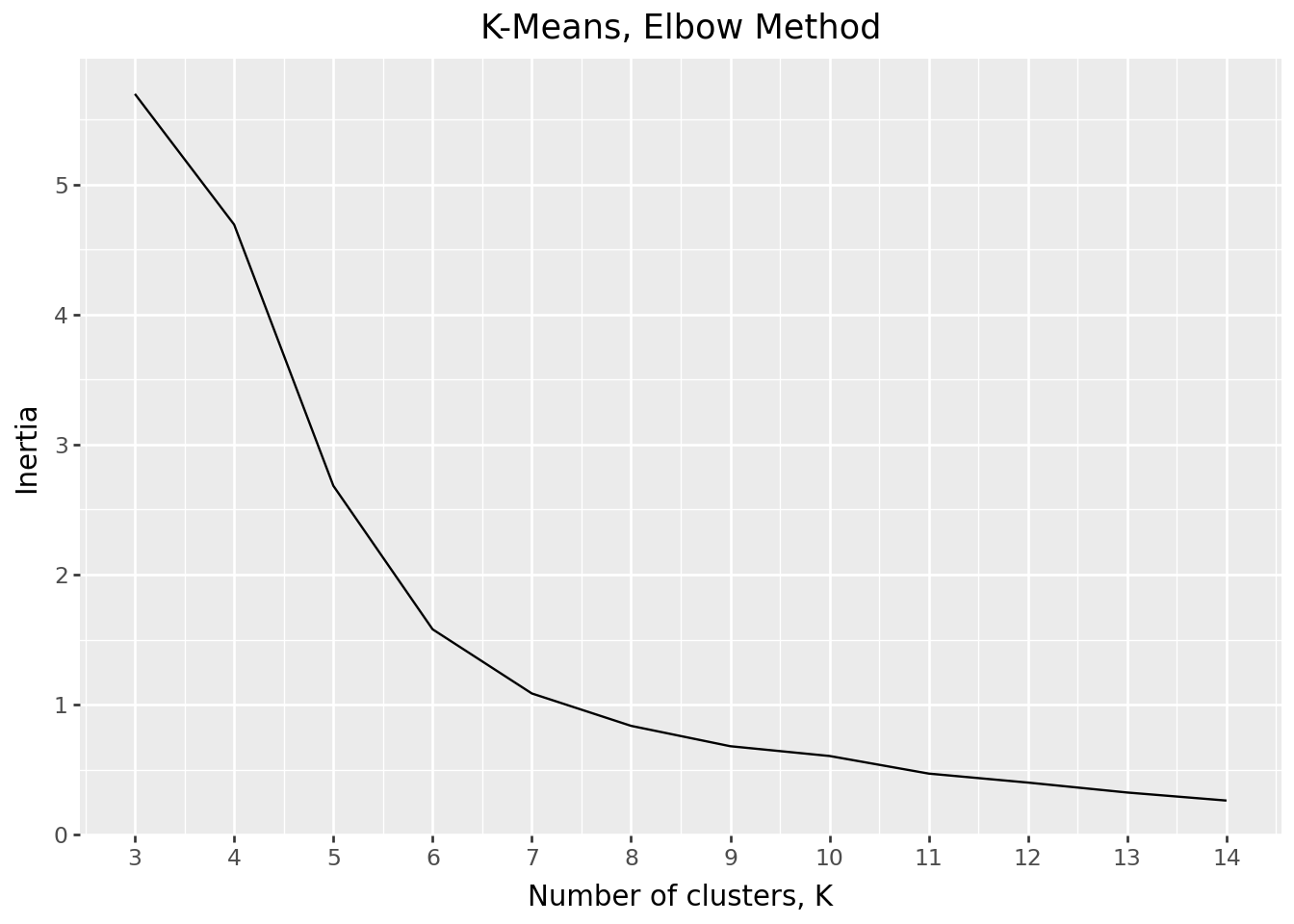
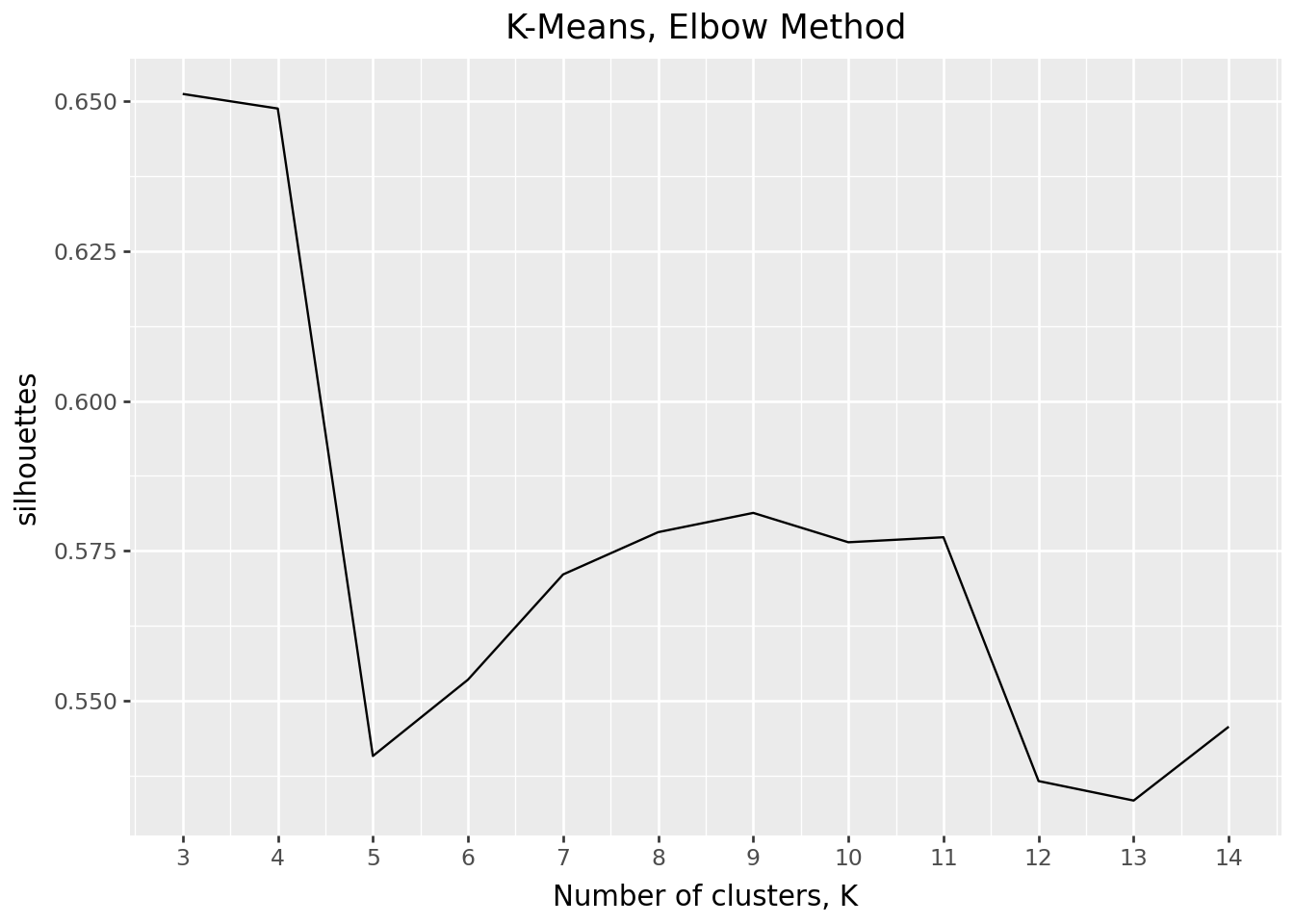
Find the Optimal K, using elbow method
In the following “elbow charts”, trade off between inertia and silhouette scores, we settle at 9 clusters, as it gives a relatively high silhouette scores whil keeping a relatively low inertia.
sp500_vol_pred = ( ibis.memtable(data=sp500_vol_pred)# adding the dates back to the volatility dataset .mutate(index = ibis.row_number()) .left_join(sp500_vol_dates, "index") .select(~s.startswith("index")))( sp500_vol_pred.aggregate( by ="cluster", count = _.thirty_day_vol.count(), mean = _.thirty_day_vol.mean(),max= _.thirty_day_vol.max(), median = _.thirty_day_vol.median(), min= _.thirty_day_vol.min()) .order_by(_.cluster))
# get a frequecy of each cluster to calculate relative frequency of each transition type, see belowsp500_cluster_vol_count = ( sp500_vol_pred.aggregate( by ="cluster", count = _.thirty_day_vol.count()) .mutate(cluster = _.cluster.cast("String")))vol_transition_table = (# perform crosstabbing between cluster_from and cluster_to to understand count of transitions sp500_vol_pred_shifted .mutate(counter =1) .pivot_wider(names_from ="cluster_to", values_from="counter", values_agg="sum", values_fill=0, names_sort=True)# add cluster frequency .left_join( right = sp500_cluster_vol_count, predicates= _.cluster_from == sp500_cluster_vol_count.cluster )# clean up data .drop(_.cluster_from) .order_by(_.cluster) .relocate(_.cluster, before="0"))vol_transition_table